FastAPI로 간단한 백엔드 어플리케이션을 구현할 일이 있었습니다. FastAPI는 어플리케이션이 떠있는 동안 event loop가 계속 돌면서 들어오는 요청을 비동기로 처리하는 방식을 사용하고 있습니다. 그래서 대부분 Service - Component 단계의 메서드들은 async로 구현되어 있습니다.
프레임워크는 이미 정해진 틀이 있기도 하고 복잡한 어플리케이션을 만든 것이 아니라서 구현에 그렇게 고생하지는 않았지만, Python에서 요청을 처리할 때 동기 / 비동기 방식에 어떤 종류가 있는지 궁금해서 찾아보았습니다. Thread / Async 개념을 Python으로 구현해 보았으며, 그 내용을 기록합니다.
내용과 그림은
- O’Reilly - Intoducing Python ch.11 병행성 파트
- Real Python - Speed Up Your Python Program With Concurrency 포스팅
- O’Reilly - Using Asyncio in Python
을 참고했습니다.
thread VS async
일반적으로 프로그램 코드를 작성하면, 들어오는 요청을 들어온 순서대로 처리하는 동기 방식을 사용합니다. 아무런 처리도 필요없기 때문에 구현은 간단하겠지만 문제는 역시 속도입니다. 앞의 작업이 오래 걸린다면 뒤에 남아있는 작업들은 하염없이 대기할 수 밖에 없게 됩니다. 이는 응용 프로그램 단계 뿐 아니라 운영체제 단계에서도 고민되어 온 문제입니다.
이를 타파하기 위해 동시성(Concurrency) 개념이 등장했습니다. 사실 멀티코어 환경이 아니라면 여러 개의 작업을 동시에 실행하는 것은 불가능합니다. 반대로 말하면 실제로 같은 시간에 특정 task나 process를 실행할 수 있는 환경은 멀티프로세싱밖에 없습니다. 다른 방식은 여러 개의 작업을 동시에 실행하는 것처럼 보이게 하는 방법이라고 보면 되겠습니다.
동시성을 구현하는 데에는 몇 가지 방법이 있지만, Thread를 늘리는 방법과 Async(비동기)를 구현하는 방식 2가지를 보겠습니다.
Thread
하나의 프로그램을 실행시키면, 운영체제는 메모리에 하나의 프로세스를 올립니다. 이 상태로 프로그램이 쭉 실행된다면, 순서대로 실행되는 동기 방식으로 실행될 것입니다.
프로세스는 일정 갯수의 Thread를 가질 수 있으며, 각 Thread는 Process에 할당되어 있는 Heap, Data, Code 영역을 공유하며 각각 작업을 실행합니다. 작업을 실행하는 단위 자체가 나뉘어진다고 보면 되겠습니다. 보다보니 근본적인 내용은 결국 개발자 면접의 사골질문 Process와 Thread의 차이가 무엇인가요?와 거의 동일합니다.
Python에서는 concurrent 라이브러리를 제공하고 있고, 이 라이브러리의 Executor를 사용해 Thread 갯수를 여러개로 늘릴 수 있습니다. Thread를 늘리면 하나의 프로세스를 효율적으로 나눠서 실행할 수 있습니다.
import concurrent.futures
import requests
import threading
import time
thread_local = threading.local()
def get_session():
if not hasattr(thread_local, "session"):
thread_local.session = requests.Session()
return thread_local.session
def download_site(url):
session = get_session()
with session.get(url) as response:
print(f"Read {len(response.content)} from {url}")
def download_all_sites(sites):
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
executor.map(download_site, sites)
if __name__ == "__main__":
sites = [
"https://www.jython.org",
"http://olympus.realpython.org/dice",
] * 100
start_time = time.time()
download_all_sites(sites)
duration = time.time() - start_time
print(f"Downloaded {len(sites)} in {duration} seconds")
ThreadPoolExecutor를 사용해 작업을 실행하고, Thread는 5개로 설정했습니다. 각 Thread에는 map 함수를 사용해 download_site 가 할당됩니다. 이 Python 파일이 실행되면 프로세스는 1개가 뜨겠지만 작업은 5개의 Thread가 나눠서 실행할 것입니다.
Session 또한 각 Thread마다 하나씩 할당되는 것을 볼 수 있습니다. Thread를 나눌 때 Session은 중요한 관리 포인트입니다. Thread는 Process의 자원을 공유하기 때문에, Thread 하나가 죽어버리면 나머지 Thread에도 영향을 주게 됩니다. 모든 Thread가 같은 Session을 공유하더라도 당연히 서로 영향을 줄 수 있습니다.
이를 방지하기 위해 많은 개발자들이 Thread-Safe한 프로그램을 작성하기 위해 노력해왔습니다. 그 중 하나로 python에서는 thread local storage를 활용할 수도 있습니다. 전역변수로 선언되어 있는 thread_local 인스턴스는 Thread별로 독립적인 네임스페이스를 사용할 수 있도록 해 Sesison 안정성을 높힐 수 있습니다.
아래 그림을 보면 하나의 Process에서 여러 개의 Thread가 요청을 처리하는 과정을 좀 더 직관적으로 이해할 수 있습니다.
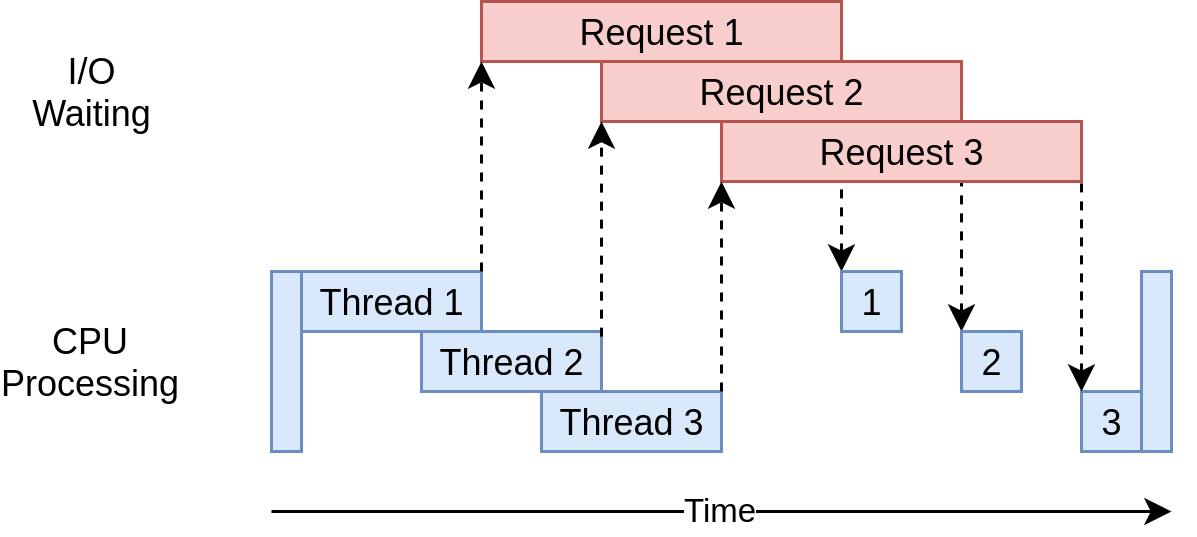
그러나 Thread가 늘어난다고 무조건 좋은 것은 아닙니다. Multi Thread는 할당된 단위의 작업을 실행하면 내려가고 또 다른 Thread가 뜨는 방식입니다. 이 때 이전 Thread의 작업이 죽고 새로운 Thread에 작업을 할당하는 교체 작업인 Context Switching이 일어나게 되는데, Thread가 너무 많아지면 과도한 Context Switching으로 인해 성능저하가 일어날 수 있습니다.
로컬 환경이나 네트워크 환경에 따라 상이하겠으나 위 예시 코드의 Thread는 약 500개를 기점으로 성능이 더 이상 올라가지 않았습니다.
# max_worker=1
Downloaded 100 in 13.254473209381104 seconds
# max_worker=5
Downloaded 100 in 3.0342769622802734 seconds
# max_worker=10
Downloaded 100 in 1.7124760150909424 seconds
# max_worker=20
Downloaded 100 in 1.1397650241851807 seconds
# max_worker=30
Downloaded 100 in 0.9560508728027344 seconds
# max_worker=100
Downloaded 100 in 0.5891621112823486 seconds
# max_worker=500
Downloaded 100 in 0.6844830513000488 seconds
또한 Python Interpreter는 Interpreter Object 여러 개가 서로 자원을 공유하면서 생길 수 있는 문제를 방지하도록 Global Interppreter Lock(GIL)을 운영하고 있기 때문에, 이를 고려하면서 멀티스레드 프로그램을 구축하는 것은 꽤 어렵습니다.
async
python에서 비동기 처리는 단일 Event loop 객체가 반복문을 돌면서 끊임없이 들어오는 요청을 처리하는 방식으로 구현합니다. 프로세스가 종료될 때까지 루프는 끝나지 않습니다.
그 순서는 다음과 같습니다.
- Event loop는 특정 작업의 제어권을 갖고 실행합니다.
- Event loop가 실행한 작업이 응답을 기다려야 한다면, 컨트롤을 버리고 다음 task를 선택해 제어권을 갖습니다.
- Event loop가 실행했던 작업이 응답을 받으면, 그 시점부터 다시 Event loop가 컨트롤을 가지고 작업을 실행합니다.
Event loop는 위와 같은 작업을 반복하는데에 있어서 작업을 정렬하거나, 작업를 Queue에 할당하는 등의 역할을 수행합니다. 적절한 비유인지는 모르겠으나 Hadoop의 namenode와 같은 자원 관리자 역할을 수행하는 느낌도 듭니다.
예시 코드는 이렇습니다.
import asyncio
import time
import aiohttp
async def download_site(session, url):
async with session.get(url) as response:
print('Read {0} from {1}'.format(response.content_length, url))
async def download_all_sites(sites):
async with aiohttp.ClientSession() as session:
tasks = []
for url in sites:
task = asyncio.ensure_future(download__site(session, url))
tasks.append(task)
await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == '__main__':
sites = [
'https://www.jython.org',
'https://olympus.realpython.org/dice'
] * 80
start_time = time.time()
asyncio.get_event_loop().run_until_complete(download_all_sites(sites))
duration = time.time() - start_time
print(f'Download {len(sites)} sites in {duration} seconds!')
파이썬에서 비동기 처리는 asyncio 라이브러리를 사용합니다. 파이썬 3.4 버전부터 파이썬 기본 라이브러리가 되었고, async과 await 키워드는 3.5 버전부터 채택되었습니다.
Thread 버전의 예시 코드는 그래도 이해가 편했는데, 비동기 코드는 이해하기가 상당히 난해합니다. 처음 보는 키워드인 async와 await가 등장하는데, 먼저 이들을 살펴보겠습니다.