[Airflow] CeleryExecutor를 사용하며 만났던 문제들
저는 상용으로 사용중인 airflow에서 CeleryExecutor를 사용하고 있습니다. 물리 서버에 띄웠을때도 MWAA를 사용할때도 그렇습니다.
CeleryExecutor는 Broker가 비동기로 요청받은 작업들을 분산처리 및 분배하는 Celery 방식을 사용해 Task를 실행합니다. Broker는 메세지를 저장하는 방식으로 queue를 사용하는데, queue는 rabittMQ나 redis, SQS 등 큐 형태의 아키텍처를 사용할 수 있습니다.
약 1년간 CeleryExecutor를 사용하면서 겪었던 문제들과 해결 or 고민중인 내용들을 정리해봅니다.
근본적인 문제
CeleryExecutor의 Worker들은 단일 머신에서 동작합니다.(물론 각각 다른 n개의 서버에 Scheduler를 통신시켜 Worker를 띄울수도 있습니다만…)
어쨌든 단일 머신에서 떠있는 Worker에 subprocess로 task가 붙게 되는데, process 간에는 리소스를 공유하지도 않기 때문에 동시에 많은 프로세스들이 실행된다면 동시성 문제가 물리적으로 발생할 수 밖에 없습니다.
실제로 제가 겪었던 문제 상황을 종합적으로 묘사하면 동시에 Task를 많이 실행했을때 자꾸 딜레이가 발생한다였습니다.
이를 타파하기 위해 등장한 것이 KubernetesExecutor라고 합니다(쿠버네티스는 전혀 모릅니다)
1. 하나의 DAG에서 Task Switching이 느릴때
1분마다 3개의 task가 실행되는 DAG이 있다고 해보겠습니다. 각 task의 실행시간이 5초~10초정도라고 하면, 3개의 task가 실행되는데 최대 30초정도이니 간격이 1분이라면 크게 문제될 일이 없습니다.
단, 하나의 task가 끝나고 다음 task로 넘어가는데 20초가 걸린다면 큰 문제가 발생합니다. 각 task의 실행시간 총합은 30초인데 DAG의 실행시간은 1분이 넘어버리기 때문에, 이전 job이 끝나기 전에 새로운 job이 시작되는 것이죠.
max_active_runs를 1 이상으로 두면 job 실행이 밀리지는 않겠지만 그것도 임시방편일 뿐, 지연시간이 계속 쌓이다보면 나중에는 새로운 Job이 실행되는데 얼마나 시간이 지연될지 알 수 없게 됩니다.
이 때 중요한건 task의 실제 작업시간 외에 드는 switching 시간입니다. 정확히는 스케줄링에 걸리는 시간이 최대한 짧아야 합니다. 이는 concurrency나 max_active_runs 옵션을 늘린다고 해서 해결하기는 어렵습니다. worker가 떠있는 서버의 리소스가 충분하더라도 스케줄링에서 버벅거리면 노는 리소스가 될테니까요.
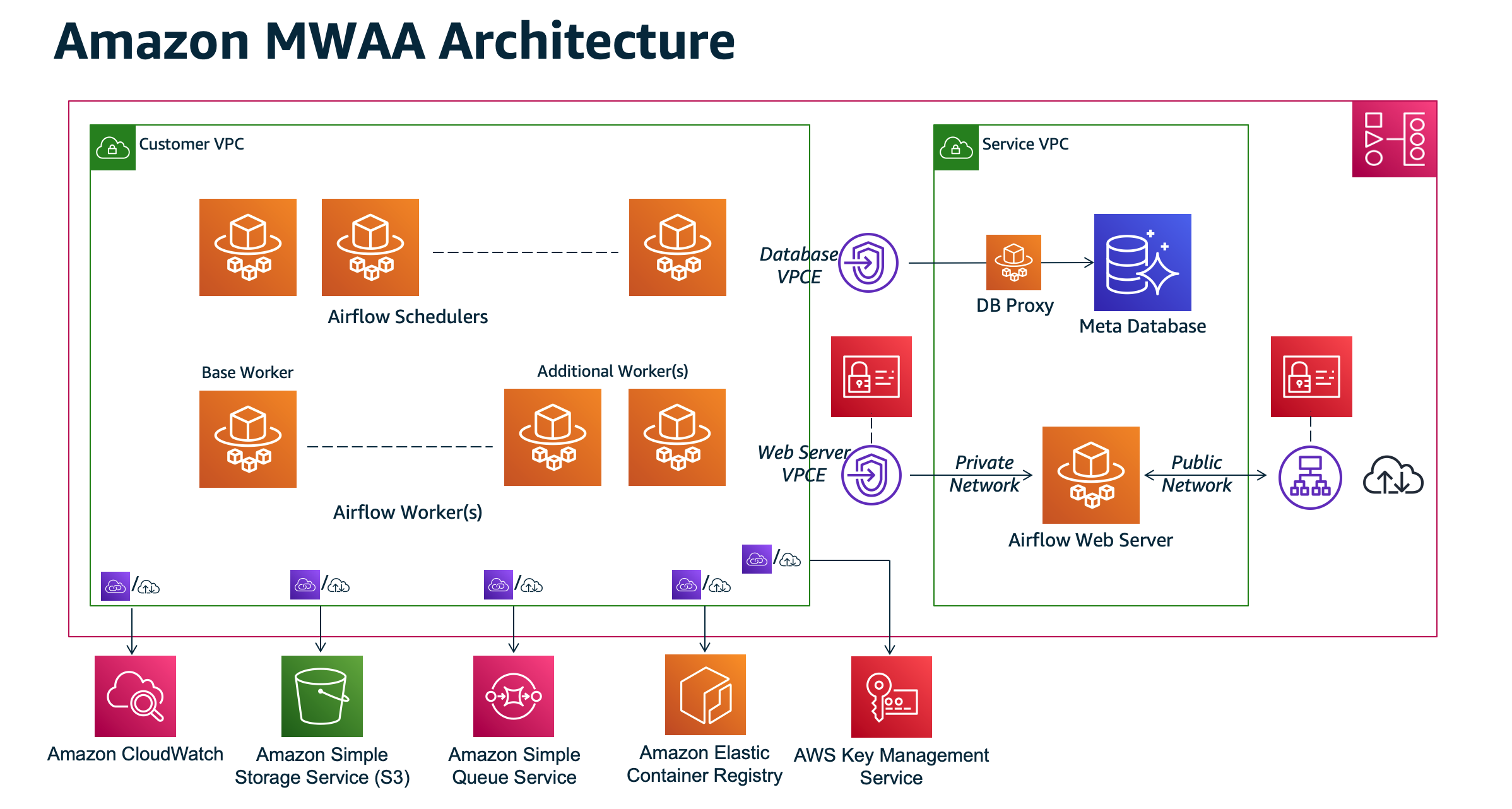
MWAA의 아키텍처이지만, 따로 서버에 airflow를 띄워도 구조가 크게 다르지 않습니다.
task 지연이 계속 발생한다면, scheduling / queueing 둘 중 하나 혹은 두군데 모두에서 오랜 시간 머무를 것입니다. worker 프로세스도 확인해봐야겠지만, 이런 경우는 스케줄러 프로세스나 사용하는 queue에서 지연이 발생할 확률이 더 높습니다.
2. 실행하는 DAG 자체가 많아질 때
CeleryExecutor 환경 아래서 실행되는 Task들은 N개의 CeleryWorker의 subprocess로 실행됩니다.