앞서 소개한 내용의 결론은
- shuffle partition을 너무 작게 잡으면 skew join이 안걸리고
- shuffle partition을 너무 크게 잡으면 skew join 이외의 작업에서 OOM을 만나기 쉽다
였습니다. transformation이 있을때마다 repartition을 크기가 맞게 해준다면 OOM을 어느 정도는 피할 수 있겠지만, 그에 따른 shuffle 비용으로 배치 시간이 상당히 길어지게 될 것입니다. skew join을 생각한다는 것 자체가 broadcast join으로는 풀 수 없는, 적어도 몇백만 * 몇백만의 join일텐데 이 큰 데이터를 매번 repartition 처리한다는 것은 상당히 부담스럽습니다.
skew가 어느정도 있더라도 하나의 job에서 skew join이 잘 동작한다면 큰 문제가 되진 않을텐데, 데이터가 불균형해질수록 skew join이 풀리거나 잘 먹지 않게 됩니다.
제가 내린 결론은 파티션 크기가 큰 join과 크기가 작은 join을 별개의 job으로 나눠서 돌리자 입니다.
파티션 크기가 큰 join은 skew join으로 파티션이 쪼개지면 좋고, 파티션 크기가 작은 join은 빨리 끝나면 좋습니다. 이 두 작업은 원하는 shuffle partition의 크기가 다릅니다. 예를 들어보겠습니다.
Table A와 Table B
join을 하다가 너무 큰데? 라는 생각이 든다면 우리는 가장 먼저 count(*) group by (join 컬럼)으로 데이터의 분포를 확인해야 합니다. Table A의 city 컬럼과 Table B의 city 컬럼을 join한다고 해보겠습니다.
Table A의 group by
Table A의 count : 약 2억건
| id | city | count(*) |
|---|---|---|
| 1 | Seoul | 45786453 |
| 2 | LA | 3567565 |
| 3 | New York | 1112345 |
| 4 | Sydney | 65789 |
| 5 | Tokyo | 12312 |
| 6 | Beijing | 978 |
| 7 | Paris | 128 |
| 8 | London | 67 |
| 9 | Berlin | 4 |
….
….
….
| id | city | count(*) |
|---|---|---|
| 1239881 | Hongkong | 1 |
Table B
Table B의 count : 약 2천만건
| id | city | country |
|---|---|---|
| 1 | Seoul | Korea |
| 2 | LA | USA |
| 3 | New York | USA |
| 4 | Sydney | Australia |
| 5 | Tokyo | Japan |
| 6 | Beijing | China |
| 7 | Paris | France |
| 8 | London | UK |
| 9 | Berlin | Germany |
….
….
….
두 테이블을 조인한다면?
두 테이블을 조인한다면 파티션의 분포는 Seoul과 LA 정도가 압도적으로 많은 부분을 차지하게 될것입니다. 점점 밑으로 내려가다가 Beijing 아래로는은 굳이 코어 하나가 할당되는 것이 민망할 정도로 작은 부분을 차지하게 됩니다. 파티션의 쏠림은 안봐도 뻔합니다.
여기서 만약 skew를 해결하기 위해 broadcast join이나 salt key를 적용한다면 어떨까요? Table B는 크기가 꽤 큰 테이블입니다. 강제로 broadcast를 걸수는 있으나, 네트워크 비용을 생각한다면 그리 효율적인 방법이라고는 볼 수 없습니다. salt key는 어떨까요? A 테이블을 10배만 뻥튀기하더라도 20억건입니다. 뻥튀기 하는 비용부터 만만치 않고, 20억건 * 2천만건의 join이 되는것 또한 그리 반갑지는 않습니다.
돌고 돌아 spark 3를 쓴다면 skew join에 의존해야 합니다. join만 있다면 skew join을 통해 큰 문제가 안되지만, 이렇게 엄청나게 쏠려있는 job은 그 이후에 repartition이나 추가적인 집계 연산에서 부담이 많이 된다고 말씀드렸는데요.
위 2개 테이블을 조인하는 가상의 job을 예시로 들고, 물리적으로 job을 분리하면 이런 그림이 됩니다.
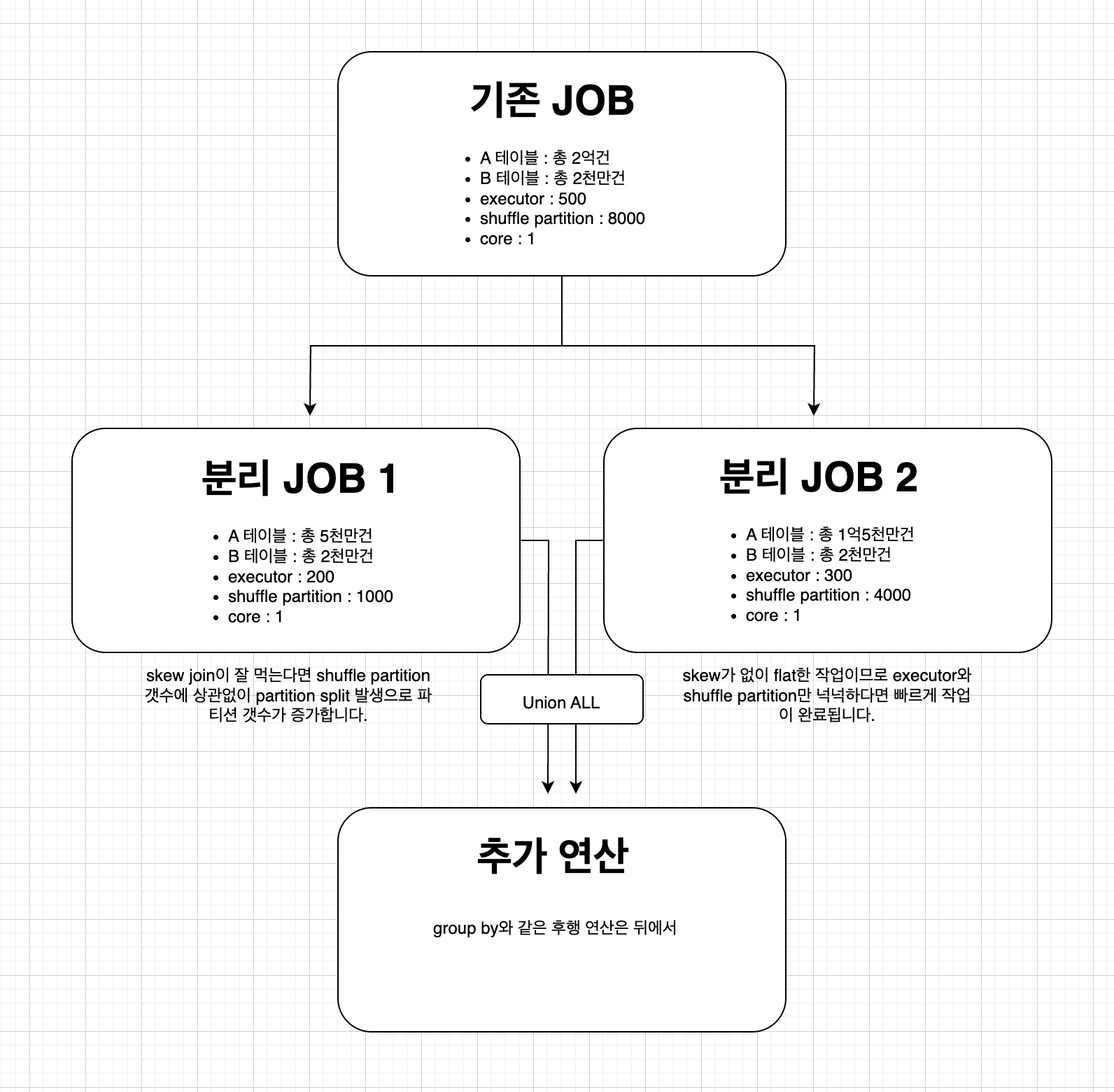
- JOB 1은 skew join을 의도하기 위해 건수가 큰 상위 n개 city의 row만 가져갑니다. skew를 심하게 유발하는 데이터들만 모여있지만 파티션의 분포가 넓지 않기 때문에 비교적 잘 풀리지 않는 skew join이 유지됩니다.
- JOB 2는 count 갯수가 많지 않지만 데이터 분포가 상당히 넓은 대다수의 row를 가져갑니다. skew가 일어나지 않기 때문에 리소스를 여유있게 분배해 빠르게 job을 끝낼 수 있도록 합니다.
이렇게 2개의 job을 만드는 것이 유지보수 측면에서는 좋지 않을 수 있습니다. 저도 처음에는 단일 job에서 with 구문 등을 사용해 분리하는 효과를 내보려고 했으나, executor 갯수가 동일하다는 가정 하에 job을 분리하는 것이 속도나 리소스 측면에서 훨씬 좋은 결과를 나타냈습니다. black box와 같은 AQE 발동조건을 최대한 안정적으로 유지하는 방법으로 봐주시면 되겠습니다.
snowflake와 같은 SaaS 툴을 보면서 최적화도 잘해주고 이런 skew도 알아서 잘 풀어주는데, 하면서 좋겠다 싶을때도 있습니다. 업무에서 impala와 spark을 자주 쓰지만 spark만큼 손이 많이 가면서 성능 내기 어려운 프레임워크도 없다고도 느끼는데요. 하지만 이렇게 내부 아키텍처를 직접 탐구하며 공부하는 것이 엔지니어링